Principal component analysis - part two
Introduction
In the first post in this series, we outlined the motivation and theory behind principal component analysis (PCA), which takes points $x_1, \ldots, x_N$ in a high dimensional space to points in a lower dimensional space while preserving as much of the original variance as possible.
In this follow-up post, we apply principal components regression (PCR), an algorithm which includes PCA as a subroutine, to a small dataset to demonstrate the ideas in practice.
Prerequisites
To understand this post, you will need to be familiar with the following concepts:
Ordinary least squares
In ordinary least squares (OLS), we want to find a line of best fit between the points $x_1, \ldots, x_N$ and the labels $y_1, \ldots, y_N$.
Denoting by $X$ the matrix whose rows are the points and $y$ the vector whose entries are the labels, the intercept $\alpha$ and slope (a.k.a. gradient) $\beta$ are obtained by minimizing $\Vert \alpha + X \beta - y \Vert$. Some matrix calculus reveals that the minimum is obtained at the values of $\alpha$ and $\beta$ for which
\[N \alpha = y^\intercal e - \beta^\intercal X^\intercal e\]and
\[X^\intercal X \beta = X^\intercal y - \alpha X^\intercal e\]where $e$ is the vector of all ones.
Principal components regression
The idea behind PCR is simple: instead of doing OLS on the high dimensional space, we first map the points to a lower dimensional space obtained by PCA and then do OLS. In more detail, we
- pick a positive integer $k < p$,
- construct the matrix $V_k$ whose columns are the first $k$ principal components of $X$,
- compute $Z_k = X V_k$, a matrix whose rows are the original points transformed to a lower dimensional “PCA space”, and
- perform OLS to find a line of best fit between the transformed points and $y$.
By the previous section, we know that the minimum is obtained at the values of the intercept $\alpha_k$ and gradient $\beta_k$ for which
\[N \alpha_k = y^\intercal e - \beta_k^\intercal Z_k^\intercal e\]and
\[Z_k^\intercal Z_k \beta_k = Z_k^\intercal y - \alpha_k Z_k^\intercal e\]Once we have solved these equations for $\alpha_k$ and $\beta_k$, we can predict the label $\hat{y}$ corresponding to a new sample $x$ as $\hat{y} = \alpha_k + x^\intercal V_k \beta_k$.
Computational considerations
Due to the result below, the linear system involving $\alpha_k$ and $\beta_k$ is a (permuted) arrowhead matrix. As such, the system can be solved efficiently.
Lemma. $Z_k^\intercal Z_k = \Sigma_k^2$ where $\Sigma_k$ is the $k \times k$ diagonal matrix whose entries are the first $k$ principal components of $X$ in descending order.
Proof. Let $v_j$ denote the $j$-th column of $V_k$. Since $v_j$ is a principal component of $X$, it is also an eigenvector of $X^\intercal X$ with eigenvalue $\sigma_j^2$, the square of the $j$-th singular value. Therefore, the $(i, j)$-th entry of $Z_k^\intercal Z_k$ is
\[(X v_i)^\intercal (X v_j) = v_i^\intercal X^\intercal X v_j = \sigma_j^2 v_i^\intercal v_j = \sigma_j^2 \delta_{ij}.\]where $\delta_{ij}$ is the Kronecker delta.
The California housing dataset
The California housing dataset from [1] has 20,640 samples and 8 predictors. For each $k \leq p = 8$, we fit using PCR on 80% of the samples (the training set) and report the root mean squared error (RMSE) on both the training set and the remaining 20% samples (the test set).
from sklearn.datasets import fetch_california_housing
from sklearn.decomposition import PCA
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
import numpy as np
np.random.seed(1)
X_all, y_all = fetch_california_housing(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X_all, y_all, test_size=0.2)
def fit(degree: int = 1):
"""Fits a PCR model to the training data.
Parameters
----------
degree: Generates all polynomial combinations of the features up to the specified degree.
Returns
-------
An `sklearn.pipeline.Pipeline` object corresponding to a learned model.
"""
pipeline = make_pipeline(
StandardScaler(),
PolynomialFeatures(degree, include_bias=False),
PCA(),
LinearRegression(),
)
pipeline.fit(X_train, y_train)
return pipeline
def rmses(model, X, y):
"""Calculates the RMSE of the model using only the first k PCs for each possible value of k.
Parameters
----------
model: The `sklearn.pipeline.Pipeline` object returned by the `fit` method.
X: An (N, p) matrix of features.
y: The corresponding (N) vector of targets.
Returns
-------
A list of RMSEs (the first entry corresponds to k=1 and the last to k=p).
"""
pca = model[:-1]
Z = pca.transform(X)
regression = model[-1]
results = []
for k in range(1, Z.shape[1] + 1):
pred = regression.intercept_ + Z[:, :k] @ regression.coef_[:k]
rmse = mean_squared_error(y, pred, squared=False)
results.append(rmse)
return results
model = fit()
rmses_train = rmses(model, X_train, y_train)
rmses_test = rmses(model, X_test, y_test)
| Rank (k) | Training set RMSE (in $100,000s) | Test set RMSE (in $100,000s) |
|---|---|---|
| 1 | 1.15492 | 1.14608 |
| 2 | 1.14128 | 1.12491 |
| 3 | 1.13947 | 1.12457 |
| 4 | 0.853976 | 0.844071 |
| 5 | 0.853972 | 0.844123 |
| 6 | 0.810381 | 0.807466 |
| 7 | 0.729905 | 0.731179 |
| 8 | 0.723369 | 0.72742 |
Both training and test set RMSEs are (roughly) decreasing functions of the rank. This suggests that using all 8 predictors does not cause overfitting.
Deriving predictors
One way to reduce the test set RMSE is to introduce more predictors into the model. Consider, as a toy example, a dataset where each sample $x_i$ has only three predictors: $x_i \equiv (a_i, b_i, c_i)$. We can replace each sample $x_i$ by a new sample $x_i^\prime \equiv (a_i, b_i, c_i, a_i^2, a_i b_i, a_i c_i, b_i^2, b_i c_i, c_i^2)$. In particular, we have added all possible quadratic monomials in $a_i, b_i, c_i$. These new entries are referred to as “derived” predictors. Note that derived predictors need not be quadratic, or even monomials; any function of the original predictors is referred to as a derived predictor.
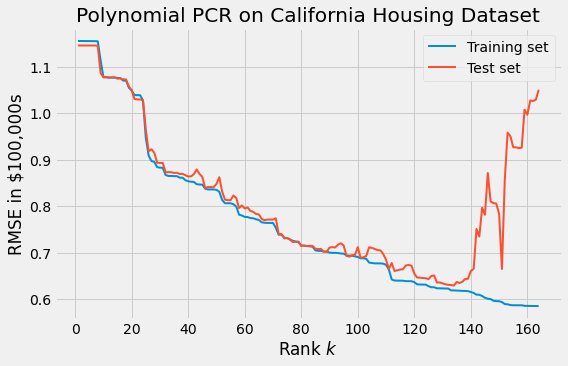
Returning to the dataset, we add all cubic monomials.
It is reasonable to expect that unlike OLS applied to $X$, OLS applied to the derived matrix $X^\prime$ will almost certainly overfit.
We plot the results (obtained by setting degree=3 in the previous fitting code) of PCR below, observing the effects of overfitting at large values of the rank.
model = fit(degree=3)
rmses_train = rmses(model, X_train, y_train)
rmses_test = rmses(model, X_test, y_test)
Bibliography
[1] Pace, R. Kelley, and Ronald Barry. “Sparse spatial autoregressions.” Statistics & Probability Letters 33.3 (1997): 291-297.